研发团队全景方法论 TechOrg Blueprint
总结图
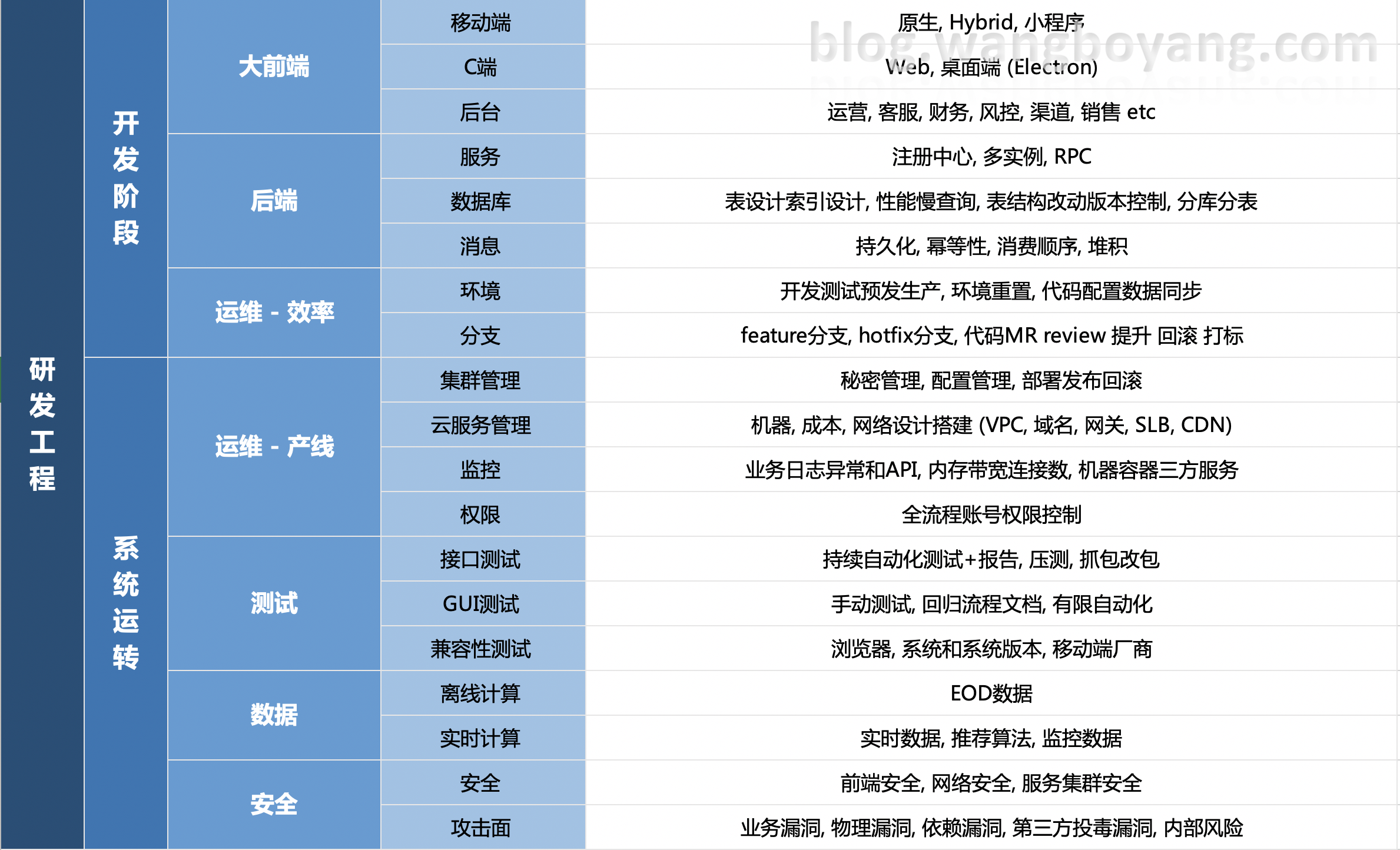


工程 Engineering
前端 Frontend
- 组件库: 关键组件自行封装 (从组件库fork抽出),
- 样式: 预处理器, 管理 Styling: Preprocessor, css-in-js, SASS, LESS
- 状态管理 State management
- 数据流 Data flow
- 脚手架 Mocking, testing, proxy, transpilation
- 代码规约 ESLint, 加在pre-push hook
后端 Backend
- Authentication, authorization, token/session management
- API design: response format, url convention
- API management: rate limiting, logging, filtering
- 代码规约 阿里IDE插件/checkstyle
数据库 Database
- Schema migration, 用简单直接的change script方式. Schema改动按序号, 合到某分支即为应用到某环境. 一段时间之后将一批Schema改动压缩合并. 每个Schema改动immutable
运维 DevOps
DevOps极为关键. DevOps is a key component to a productive RnD team.
-
Kubernetes集群, 采用Rancher管理, 包括, 滚动式发布, 回滚, 扩缩容, 秘密管理等. 每个环境一个命名空间. Ingress来对外暴露服务
-
分支模型 / 部署流水线, 每个环境对应相对的分支, 合并到X分支即用钩子发布到X环境. 同时不同环境的不同配置也在代码仓库提现, 除了秘密直接写在集群除外. 构建jenkins根据钩子开始特定环境的构建, 依赖包也根据环境后缀采用对应环境的版本. 构建完毕后推送镜像, 并在对应环境集群命名空间设定镜像. Branching / Deploy pipeline
-
发布管理 / 版本管理, 合并到master分支, 即合并stage环境. stage环境高度拟真生产环境. 生产环境镜像只能来源于stage提升. 每次发布, 对master分支打tag. Release management
-
监控, 包括容器监控 (进程, 资源, liveness/health), 集群机器监控, Java进程监控, 业务接口监控, 区块链块高监控, 区块链地址余额监控
-
数据库, 中间件, 机器, 域名DNS, 邮件短信等管理在云服务上
-
运维几个基本原则: 自动化 - 运维不是操作员, 工具化 - 引入工具审慎一旦引入妥善使用, 代码化 - 所有脚本配置进repo, 安全与权限
安全 Security
测试 QA
- 接口自动化测试
- 回归测试流程
量化 Quant
- 做市
- 做量 (K线, 盘口, 盘口大小要和最小diff比对)
- 监控
流程 Procedures
-
一把手决策并负责. One ultimate decision maker with >50% voting right.
-
每日站会,
DONE, WIP, TODO. 每周周报, 同样内容形式, 按bullet points整理发布. Daily Standup, reportDONE, WIP, TODOin round-robin. Weekly, same content in bullet-point format, compiled and sent on last day of the week. -
每周一11点需求评审会. 每周四完成验收回归测试, 周五早进行发布. 每月allhands全体会. Weekly requirement review meeting on Monday 11am.
-
任务状态: 待确认 - 待开发 - 开发中 - 待测试 - 已完成; 已关闭. 任务的创建和更新要有提醒机制, Teambition的桌面提示或是发送到钉钉频道. Task FSM: ToConfirm - ToDev - WIP - ToTest - DONE; CLOSED.
-
整体开发流程描述:
- 产品产出需求, 通常周五, 最晚周一准备好. 产品创建粗粒度需求并放入待确认流水线. 确认清晰后移入待开发, 分配给tech lead.
- tech lead分配到部门leader, 部门leader到开发, 开发移到开发中.
- 从develop分支按任务号拉出feature分支, 同一个需求在不同仓库用同一个名字. 数个需求有依赖关系的可以用同一个分支.
- 测试联调需要的, 从feature分支合并到环境分支来自动部署, 如dev1 dev2 test1 test2. 在环境中测试无误后通常是合适时机开所有相关PR, 从feature分支到develop.
- Reviewer理清依赖并都合并到develop, 进一步提升到master, 此时自动部署stage预发布环境. 所有变更进stage后跑自动化用例以及回归流程. 完成后最终打tag, 并直接从stage镜像提升到prod. 发布完成.
- 每一个发环境, 合PR, 提升镜像的操作都伴随相应表结构, 跑脚本和配置的改动. 这部分在单独release repo管理, 如
test1 - 101-add-country-col-to-users-table.sqlprod - 100-fill-new-col-clientid.sql, 记录每个环境的情况. - 后续tech lead和部门leader根据需要再拆分需求, 分配到下一级 (如果不跨sprint, 倾向于尽量不拆过细, 一个大需求一个人, 自行管理).
- 遇到线上bug的, master分出hotfix分支, 合并回master, 在stage环境校验, 打tag提升到prod, 并合并回develop.
- 过程中有其他紧急需求的, 随时沟通随时排期, 走以上需求流程精简版.
- 根据实际经验, 未引入flyway等, 因为环境状态包含队列缓存数据库结构和数据配置秘密乃至落盘快照hadoopHDFS等, 单个工具无法全部管理.
团队 Team
招聘 Recruitment
-
两级技术架构中, 优先招聘各个部门的leader: 大前端, 后端, 数据, 运维, 测试. 之后招聘面试工作可以更专业工作量向下分布. 吸引到这些leader需要很多时间精力去吸引, 还需要一些运气. 当缺乏相关专业知识判断某个候选人的时候, 1. 请其他人支援 2. 更多信任背景和工作经历, 对于在前公司的项目经历和工作成果要仔细推敲. 如果一上来不能填补这些空缺, 可以先招基层过渡.
-
招聘: 采用笔试, 笔试中有详尽的测试用例. 全部跑通用例通过. 然后看代码, 代码讲道理负责任, 做面试. 面试中技术考察之外, 也注重人的反应速度, 学习能力, 沟通能力, 解决问题能力. 宁缺毋滥, 不要让自己后悔 - 感受这个人的性格为人, 问自己是不是想和这个人共事, 这个人是不是符合团队的氛围和气味 (阿里将之称为阿里味).
-
不否认很多时候要对招聘质量和速度进行取舍. 有的时候种种因素之下, 需要作出一两个降低标准的招聘. 此时需要思考好后续步骤, 是作为基层人员, 还是有计划有考核地汰换.
-
实际中, 一个工程师的实际工作方式以及和团队的融合, 在面试中顶多体现四成. 在入职后的前一两周中, 才能对一个人有准确的判断. 此时如果决定不合适, 长痛不如短痛. 应当与这个员工及早谈话明确, 如果不能有改善则要离开, 给予对方铺垫, 改进的机会, 和心理缓冲. 另外, 大多数商业环境中不能支持普遍的试岗 (如前两星期), 但这不失为一个值得尝试的制度, 有成功的先例.
-
整体工程能力和职业素养胜于具体技能.
-
Direct report倾向于每月1-on-1沟通想法和绩效分数.
薪酬, 职级, 绩效 Compensation, Progression & Performance
-
从经验看, 秘薪制是最不坏的一种选择. From experience, it’s wise to keep compensation strictly confidential. It’s hard but let’s do as much as possible.
-
绩效评价频率有月度, 季度, 半年度三个选项.
-
沿用阿里职级序列, 名称与代码如下. 增加正式的+级别, 增加晋升频率和体感.
- P4/P4+ 初级工程师
- P5/P5+ 工程师
- P6/P6+ 资深工程师
- P7/P7+ 专家
- P8/P8+ 资深专家
- P9/P9+ 总监
- P10/P10+ 资深总监
技术团队影响力与建设
影响力是行业常用的提法, 可用于tech lead个人或团队
-
影响力直接作用于招聘, 效果显著. 一个有博客, 有过硬开源项目, 有会议演讲分享的技术团队, 对技术人员的吸引力是巨大的. 参考阿里数据流形团队: https://zhuanlan.zhihu.com/FrontendPerusal https://zhuanlan.zhihu.com/purerender https://github.com/dt-fe/weekly https://github.com/recharts/recharts https://news.ycombinator.com/item?id=12277389 https://github.com/nefe/Hiring
-
建设影响力的过程中采取的常见方式: 开源项目, 写博客专栏, 出版书籍, 在外部会议演讲分享, 在内部组织学习技术分享, 申请专利. 这些方式对团队现有成员也有很好的学习提升, 提振士气作用.
-
业务需求与技术影响力建设在时间上是一对矛盾. 谷歌的做法是20%, 阿里的做法是业务项目必须满足, 技术项目决定更高绩效和晋升.
Culture & Conventions 文化与规范
Culture 文化
-
开发为创造价值. We don’t develop for sheer pleasure. We develop to create value.
-
名称极为重要. It’s very important to get names and terms right - especially for RnD purposes. A clear reference to matter & concepts lays the foundation of all communication.
-
文化规约很重要 - 提效, 推进, 减少错误. 每件事有法可依, 减少决策精力损耗. It’s important to have conventions & standardizations. Vastly accelerates all activities and reduce errors. Let’s have them even for small things like writing, commit message, emails.
-
什么时候做自动化? 当节约的手动时间数倍于开发所需时间时. 同时要考虑到自动化牺牲的灵活性. Automation is good. Let’s have it as much as possible, without losing flexibility and knowledge.
-
用轻量级通知广播信息, 让知识共享, 让每个人同步, 保持每个人的参与感与活力. 口头与面对面交流也能高效达到同一结果. Lightweight FYI notifications are good. They keep everyone on the same page, and they keep everyone active and outspoken. Verbal and face-to-face communications are also good.
-
好的文档和SOP应当: 简洁, 只记录主干信息和决定; 不容易过时, 不需要巨大成本维护; 有用, 有查阅价值. 典型例子如新人入境文档. 典型的好的保存方式是把和某个仓库相关的文档以Markdown格式提交到该仓库中.
-
提交一切有用信息到仓库 - 包括脚本, 文档, 生成的批量mock数据, 常用的本地配置, 测试尝试代码 (进unittest). secret和会产生冲突的除外. Everything, with almost no exception (perhaps secrets and conflict-prone files), should be in the codebase so that they are persisted and version-controled.
-
遇到问题30分钟不能解决再求助. As a capable and proud engineer, solve the problem as much as possible and only ask for help when you can’t solve after 30mins of grepping.
-
单点简化. 一个工具, 一个平台, 一个沟通渠道. 要搜要查的位置就减少. Less places to look for info. Less modes of communication. Less number of tools that serve the same purpose. Single point of truth.
-
引入任何工具会产生运维管理成本. 要么不引入用最简单直接清晰的方式管理 (procedure + md文本), 要么用好用充分每个引入的工具 (例: gitlab钩子, 钉钉通知从开会到线上告警, 钉钉考勤HR流程报销, jenkins各式任务, kibana日志维度等).
-
一致性. 所有的命名一致, 任何环境, 只要有可能, 都最好一致. 如果开发测试是docker里跑的mysql, 线上是RDS, 其中的subtle difference一旦踩到是痛不欲生.
规范 Conventions
-
We refer to the method of text-based searching, code searching, googling, chat history searching as a whole as grep grepping.
-
Use correct casing. When starting a sentence, prefer capitalize.
-
Simple English. Comfortable and clear meaning. Use America spelling because it’s shorter.
-
巨量的重复的容量加入仓库会造成搜索困难和效率下降. 只有强原因才允许加入大量外部文本进入代码仓库. Text search is a great tool for engineers, and info flooding is its biggest enemy. Do not add enormous amount of code/text/info without strong justification.
-
开PR, 早开, 多开, 开小PR. 同一个分支的PR会自动更新, 不需要合的时候标WIP. Incremental improvement - 几十个文件几千行的PR说code review就是形式
-
不回避外包. 两个时间节点是适合外包介入的时期: 早早期人员未到位 (交易所) or 业务大发展时期大量重复业务开发 (阿里云). 阿里至今采用大量外包
-
时间戳. 所有前后端涉及时间, 一概用时间戳 (Long), 到毫秒. 对应后端系统 UTC. 前端根据用户时区转换成时间 (各类库都会自动处理). 跨时区多的项目的, 必须注意严格遵守
API接口
Response
{
"status": "success" | "failed" | "error",
"code": "" | "SERVICE_OPSCONFIG_RATE_LIMIT",
"data": {}
}
status, code, data三个字段, 所有接口所有情况都必须存在. code和data可以为空. 当status=success时, code往往为空 (也可以不为空). 当code!=success时, 如果有详细错误数据, data不为空
failed一般是业务失败, 比如密码错误, 找不到用户等. error是系统失败, 比如超时
错误码code格式: SERVICE (代表服务来自单个微服务) +
比如social服务中, 某个表单提交校验错误. 由于其中年龄字段age范围是 16-120, 用户填写了-1. 返回值就可以设计为:
{
"status": "failed",
"code": "SERVICE_SOCIAL_INVALID_PARAM",
"data": { "field": "age", "reason": "Field age must be within range 16-120" }
}
Request
GET请求有url param POST请求有body 由于前缀 (用于proxy), 后缀 (版本号v123), 不加入path variable 需要auth的接口, 带Authorization header
Commit Message
建议使用前缀, 用来分类commit. 最大的好处是在浏览历史的时候能快速区分定位到有可能有影响的提交, 跳过不相关的提交.
FEATURE
FEATURE WIP
FEATURE DONE
FIX
CONFIG
LINT
DOC
TEXT
DATA
BUILD
举例
FEATURE 代表实现功能的代码提交, 可以很简洁, 也可以加一些说明, 例
FEATURE 刮卡 FEATURE 添加接口错误统计和日志打点 FEATURE 添加主页游戏列表底部No more
FEATURE WIP 代表功能做到一半 Work in Progress, 这个提交状态的代码应该是可以跑的, 不要break, 但是新功能还没做完还没生效. 例
FEATURE WIP 刮卡建立了实体类, 增加了API, 还未调用
FEATURE DONE 代表某个功能做完了, 也可以很简洁, 例
FEATURE DONE 刮卡
FIX 修复问题的提交, 一般这种提交一定要后面有说明, 是比较容易需要事后查询的, 不管是自己还是别人查. 例
FIX 历史遗留(非常老)的代码中, 各种命名里面category的拼写是错的categroy, 改对之后产生了很多问题, 回滚了 FIX 修复磁盘空间大小检测的打点
CONFIG 只改了一些配置类的提交, 典型的比如改版本号, application.yml, AndroidManifest等. 可以比较简洁. 例
CONFIG 修改targetSdkVersion=28
LINT 代码格式, 空格缩进, import分组排序, 删除无用文件代码等. 这种提交要确保除了改代码规范啥别的都不改. 信息可以很简单, 只有前缀也可以. 例
LINT 单行if也要花括号
DOC 加文档加注释加Readme. 这种提交要确保除了文档啥别的都不改. 信息可以很简单, 只有前缀也可以. 例
DOC controller加文档注解
TEXT 各种改文案, 例
TEXT 修改我玩过的游戏文案
备注
如果提交比较特殊 (例如 Initial commit), 可以添加一个新前缀, 也可以考虑不采用前缀. 但不能采用了错误前缀
比如一个提交信息就一句CONFIG, 实际改动几十个文件几百行. 或者一个提交名字叫LINT, 实际还顺手改了代码逻辑, 会坑自己
阿里技术管理体系观察
阿里技术团队稳定性高, 特别是越资深越稳定; 能打仗, 能抗加班; attachment强, 团队内同事很多交往深入, 无话不谈. 对此的一些观察与思考:
- 对于早期一批员工, 承认发展是硬道理. 员工与业务, 公司, 城市 (杭州) 一同成长, 收益大, 当然全心认同
- 对于现阶段员工, 特别是基层员工, 并不能享受到这些红利. 例, 17年底的时候, 旁边一个应届就来阿里待了3年的前端研发, P5, base是18k
个人观察到两个点起到了作用:
-
融合荣誉感和江湖地位的晋级体系. 职级和晋级是阿里一件大事, 和绩效/奖金/年资都有联系. 晋升中, 涨薪只是一部分激励, 更大的是荣誉感, 地位, 爽感优越感. 晋升是加班时的胡萝卜, 也是促使员工一年一年留下的胡萝卜 - 至少升到7再走吧, 等等. 辅助搭配这个点的机制包括: P级写到钉钉和内网上显眼位置全部开放可查, 不按工作年限而是按在阿里的时间长短论资排辈, 不庆祝生日而是庆祝每个人入职100天, 1年, 2年等节点, 一年香三年醇五年陈等. 生日自有各种假惺惺的电商/招行/饭馆理发店鞭炮齐鸣发来庆祝 (和优惠券)
- 晋升机制是:
- 每半年有一个绩效评分, 年中一次年底一次. 绩效在3.75以上同时还有直接主管推荐可以参评晋升. 一般都是年底之后晋升, 极少数特殊情况在年中走绿色通道能晋升
- 同时绩效3.75能拿6个月年终奖
- 年终奖发放是3月-4月. 5月晋升季, 准备ppt, 其他部门leader列席答辩
- 如果通过, 晋升7月1号生效
- 所以为了拿年终奖, 阿里的人4月前不会离职. 有希望晋升的, 7月1号之前也不会离职
- P级别名称见上. 一般本科毕业应届是P5例外的可以到P6. 研究生应届P6, 博士应届P6例外的可以到P7. HR内部有P5+ P6+等中间级别, 在钉钉和内网上不体现
- 阿里特色的同事即家人, 公司即社交的bonding模式. 阿里有内部相亲会 (阿里日), 不避讳乃至隐隐鼓励内部员工恋爱. 鼓励员工周末团建, 让员工在杭州同事和朋友是一拨人. 加班和努力工作的动力往往为: 在喜欢的人面前表现自我, 不要让同事失望, 不要拖累团队, 人情/面子等. 加班也变成了”男女朋友两人一块下班”, “中午能和朋友碰面吃饭聊天吐槽”. 加班时买零食水果, 等发版的时候聊天开黑, 加班在气氛和内容上和去唱K开party比较类似了. 搭配这个点的机制包括两周百阿培训, 公益/团建的活动, 很多项目加班经费, 阿里日相亲内网论坛相亲等.
Across the GFW
大陆与海外网络互通是大多数开发者在国内的公司要面临的问题
开发与使用角度
VPN一般有以下几种方案
- 自搭或供应商搭VPN, 采用某种还未被封的混淆协议 (SSR, Trojan, v2ray). 稳定性速度都堪忧, 如果自搭, 维护工作量不小, 每次挂了都很烦
- 拉专线, 找半官方的供应商, 现在标准价格大约 5000rmb/4Mbps*月. 协议透明方便官方监管, 贵, 带宽有限, 但是延迟低畅通无阻
- 大型外企, 自贸区等去工信部挂号拉全局方案, 不是所有公司都可行, 略过不表
运维与架构角度
一个典型的构建过程可能如下例:
def main():
curdir = os.path.join(basedir, project)
now = datetime.datetime.now().strftime('%Y%m%d-%H%M%S')
run('git pull', curdir)
run('rm -rf %s %s'
% ('/root/.gradle/caches/modules-2/files-2.1/works.atem/',
'/root/.gradle/caches/modules-2/metadata-2.71/descriptors/works.atem/'), curdir)
run('gradle build publish', curdir)
if project not in ['abe-base']:
run('aws ecr get-login-password | docker login --username AWS --password-stdin 224059377248.dkr.ecr.us-east-1.amazonaws.com',
curdir)
run('docker build -t %s %s' % (project, curdir), curdir)
run('docker tag %s:latest 224059377248.dkr.ecr.us-east-1.amazonaws.com/%s:%s'
% (project, project, now), curdir)
run('docker push 224059377248.dkr.ecr.us-east-1.amazonaws.com/%s:%s'
% (project, now), curdir)
run('sleep 2', curdir)
run('kubectl set image deploy %s %s=224059377248.dkr.ecr.us-east-1.amazonaws.com/%s:%s -n abe-dev'
% (project, project, project, now), curdir)
看每一步的connectivity:
- 拉代码 - 连gitlab
- 构建拉依赖 - 连nexus
- 发布jar - 连nexus
- 发布docker image - 连ecr
- 更新集群 - 连eks
只要用户在海外 - 服务器集群在海外 - 用到的第三方服务 (Facebook login等) 在海外, 然后开发肉身在国内, 那跨国这个动作就一定会发生. 生产集群放国外/开发测试集群放国内的想法有意义, 但是跨不过 1. 第三方服务 2. 必须域名备案才能走国内服务器. 此外, 依照一致性原则, 开发测试环境和生产环境最好保持高度一致.
这个跨国动作可以发生在中间环节. 比如说, 不要让海外服务器拉, 改成国内服务器推. 推的内容取决于在哪一步跨国, 比如可以推源码zip包, 或者推bootJar. 前者更小, 但是意味着拉nexus依赖又有速度问题. 后者较大, 几十mb到一百多mb的量级, 考验出国上行带宽.
检验过行之有效的一个方式是, 所有通讯推到开发者这个环节. 国内开发者从海外gitlab拉和推代码, 是慢的, 但是代码是体积相对最小的. 之后所有构建发布全在云端VPC进行, 直到一个钉钉消息推送过来”xx环境部署完成版本xx”, 然后去访问和测试. 不完美, 但是失败在本地 (比如翻墙工具断了) 比失败在云端 (构建服超时报错) 更明显更容易解决一点. 可以问问旁边人, 在你这块是不是好的.